- Home /
- Academy /
- Technical SEO /
- Robots.txt - A Beginner's Guide to SEO
Robots.txt - A Beginner's Guide to SEO

What is a robots.txt file?
A robots.txt file contains instructions for bots. Most websites include this file in their source code. Because bad bots are unlikely to follow the instructions, robots.txt files are mostly used to manage the activities of good bots like web crawlers.

Consider a robots.txt file to be a "Code of Conduct" sign posted on the wall of a gym, a bar, or a community center: the sign has no power to enforce the listed rules, but "good" patrons will follow them, while "bad" ones will likely break them and be banned.
How does robots.txt file work?
A robots.txt file is simply a text file that contains no HTML markup code (hence the .txt extension). The robots.txt file, like any other file on the website, is hosted on the web server.
The robots.txt file for any given website can usually be accessed by typing the full URL for the homepage followed by /robots.txt, such as https://www.pagesmeter.com/robots.txt.
Because the file isn't linked to anywhere else on the site, users are unlikely to come across it, but most web crawler bots will look for it before crawling the rest of the site.
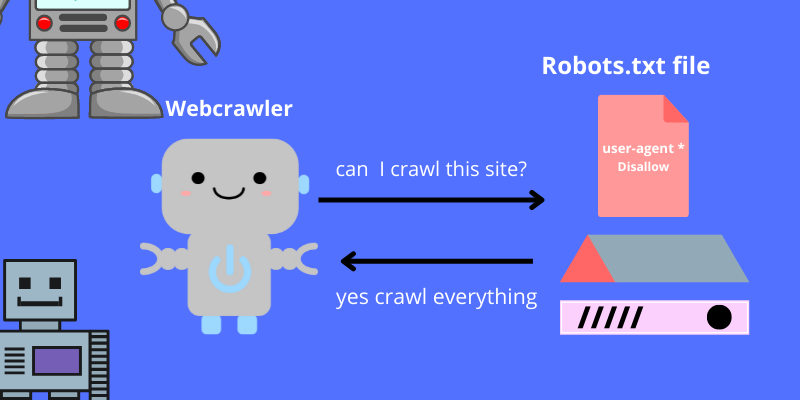
A robots.txt file can provide instructions for bots, but it cannot enforce those instructions.
Before viewing any other pages on a domain, a good bot, such as a web crawler or a news feed bot, will attempt to visit the robots.txt file and will follow the instructions.
A lousy bot will either ignore the robots.txt file or process it to find the forbidden web pages.
The most specific set of instructions in the robots.txt file will be followed by a web crawler bot.
If the file contains contradictory commands, the bot will follow the more granular command.
What are the protocols used in the robots.txt file?
A protocol is a format for transmitting instructions or commands in networking. Robots.txt files employ a variety of protocols.
The primary protocol is known as the Robots Exclusion Protocol. This is a method for bots to know which websites and resources to avoid.
The robots.txt file contains instructions formatted for this protocol.
The Sitemaps protocol is another protocol that is used for robots.txt files. This can be thought of as a protocol for robot inclusion.

Sitemaps inform web crawlers about which pages they can access. This helps to ensure that a crawler bot does not overlook any important pages.
Why should you be concerned with robots.txt?
From an SEO standpoint, the robots.txt file is critical. It instructs search engines on how to crawl your website most effectively.
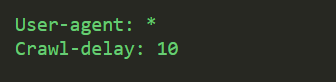
You can use the robots.txt file to prevent search engines from accessing specific parts of your website, prevent duplicate content, and provide search engines with helpful tips on how to crawl your website more efficiently.
Changes to your robots.txt file, on the other hand, have the potential to make large portions of your website inaccessible to search engines.
Best practices for robots.txt for SEO
Follow these guidelines to properly manage the robots.txt files:
(i) Don't hide content that you want to be tracked.
You should also not block sections of the website that should be tracked.
(ii) Keep in mind that bots would not follow links to pages that have been blocked by robots.txt.
The linked resources will not be crawled and may not be indexed unless they are also linked from other pages that search engines can access because they have not been blocked.
A link value cannot also be passed from the blocked page to the link destination. If you want to grant authority to specific pages, you must use a locking mechanism other than robots.txt.
(iii) To avoid showing confidential data on the search engine results page, do not use robots.txt.
Other pages can link directly to the personal information page (thereby avoiding the robots.txt guidelines in your root domain or home page), allowing it to be indexed.
To prevent the page from appearing in Google search results, use a different method, such as password protection or the index meta tag.
(iv) Keep in mind that some search engines use multiple user agents.
For example, GoogleBot is used for organic search and GoogleBot-Image is used for image search.
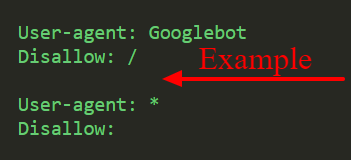
Because most user agents from the same search engine follow the same rules, you don't need to specify guidelines for each search engine crawler, but doing so allows you to control how the site content is crawled.
(v) The search engine caches the content of the robots.txt file, but it typically updates the cached data daily.
If you make changes to the file and want to update it quickly, send the robots.txt URL to Google.
What are the disadvantages of the robots.txt file?
Finally, we'll look at the factors that limit the functionality of the robots.txt file:
(i) Pages will still appear in search results.
Pages that are inaccessible to search engines due to the robots.txt file but contain links to them may appear in search results from a crawlable page.
(ii) Only directives are included.
Google values the robots.txt file, but it is only a suggestion, not a requirement.
(iii) File Dimensions
Google limits the size of robots.txt files to 521 kilobytes, and if the content exceeds this limit, it can ignore it. We don't know if other search engines place a limit on these files as well.
(iv) Robot.txt is compressed for 24 hours.
According to Google, the robots.txt file is typically cached for up to 24 hours. Something to keep in mind when editing the file.
Conclusion
Robots.txt is a straightforward but effective file. If used correctly, it can have a positive impact on SEO.
To increase your site's exposure, make sure search engine bots are crawling the most relevant information. As we've seen, a properly configured WordPress robots.txt file allows you to specify how those bots interact with your site.
As a result, they will be able to provide more relevant and useful content to searchers.
Start using PagesMeter now!
With PagesMeter, you have everything you need for better website speed monitoring, all in one place.
- Free Sign Up
- No credit card required
The hreflang attribute is used to specify which language your content is in and which geographical region it is intended for.

A search engine spider has a "allowance" for how many pages on your site it can and wants to crawl. This is referred to as a "crawl budget."

The URL redirect also known as URL forwarding is a technique to give more than one URL address to a page or as a whole website or an application.
Uncover your website’s SEO potential.
PagesMeter is a single tool that offers everything you need to monitor your website's speed.