- Home /
- Academy /
- Technical SEO /
- The Essential Guide to Meta Robots Tags
The Essential Guide to Meta Robots Tags

Generally getting search engines to crawl and index your website the way you want can be difficult. While robots.txt controls the accessibility of your content to crawlers, it does not tell them whether or not to index it. That is the purpose of the robot's meta tags and the x-robots-tag HTTP header.
Meta robot tags are an essential tool for improving search engine crawling and indexing behavior and controlling your SERP snippets.
This blog will explain how to do so, how search engine interpretation and support differ, and how the meta robots tag relates to the X-Robots-Tag and the robots.txt file.
What is a meta robot tag?
Robots' meta directives (also known as "meta tags") are pieces of code that instruct crawlers on how to crawl or index web page content. Whereas robots.txt file directives suggest how bots should crawl a website's pages, robot meta directives provide more specific instructions on how to crawl and index a page's content.
There are two kinds of robot meta directives: those that are embedded in HTML pages (such as the meta robots tag) and those that the web server sends as HTTP headers (such as x-robots-tag). The same parameters (i.e., the crawling or indexing instructions provided by a meta tag, such as "noindex" and "nofollow" in the preceding example) can be used with both meta robots and the x-robots-tag; the only difference is how those parameters are communicated to crawlers.
Meta directives instruct crawlers on how to crawl and index information found on a specific webpage. If bots discover these directives, their parameters serve as strong suggestions for crawler indexation behavior. Crawlers, like robots.txt files, are not required to follow your meta directives, so it's safe to assume that some malicious web robots will ignore your directives.
Why is a meta robot tag important for SEO?
The meta robots tag is commonly used to prevent pages from appearing in search results, but it has other applications (more on those later).
You may want to prevent search engines from indexing the following types of content:
- Thin pages that provide little or no value to the user;
- Pages in the development environment;
- administrative and thank-you pages
- Results of an internal search;
- Landing pages for PPC;
- Pages with information about upcoming promotions, contests, or product launches;
- Content duplication (use canonical tags to recommend the best version for indexing);
In general, the larger your website, the more you'll have to manage crawlability and indexation. In addition, you want Google and other search engines to crawl and index your pages as quickly as possible. Combining page-level directives with robots.txt and sitemaps correctly is critical for SEO.
How does the meta robots tag work?
The tag has two parts, as you can see: name=" and content=".
The name part, like the user-agent line in a robots.txt file, specifies the user-agent of the bot you're instructing. In contrast to robots.txt, you do not include all bots by using a wildcard character. Simply type "robots" to accomplish this. As a result, the tag meta robots were created.
The second part, content="," tells the bots what to do
What meta robots tag values are there?
There are numerous values that can be entered into the robots tag's content field. Each of these values performs a distinct function:

Index:
This instructs search engines to index the page. This may appear to be pointless at first glance because "Index" is the default, but it can be useful if you only want a specific group of search engines to index the page.
Noindex:
Search engines are told not to index the page, so it will not appear in search results.
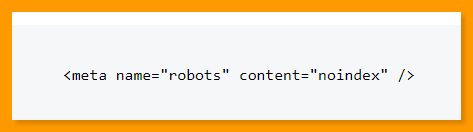
Noimageindex:
This tag instructs search engines not to index the images on a page. However, if that image is added elsewhere on the web, Google will still index it and display it in image search results.
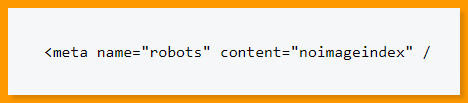
None:
This is a shorthand for "noindex, nofollow." It instructs search engines to ignore the page and pretend it never existed.
Follow:
Search engines are instructed to follow any links found on the page. This is the default status when a bot cannot find a meta robots tag that applies to it, as with "Index."
Nofollow:
This instructs search engines not to follow any links on a page. You can also add this value to a single link.
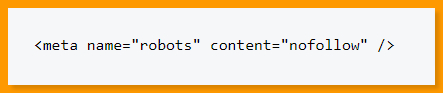
Noarchive:
This instructs search engines not to display cached copies of the page.

Nocache:
The same as "NoArchive," but used by MSN/Live.
Nosnippet:
This setting prevents search engines from including a snippet for this page in search results. They are also prevented from caching the page.
Notranslate:
This instructs search engines not to display translated versions of the page in search results.
Unavailable_after:
Search engines are instructed not to display the page in search results after a certain date.

NoYDir:
This instructs the search engine not to use the page description from Yahoo! Directory in the search snippet.
NoODP:
Prevents search engines from using the DMOZ page description in the search snippet. The Open Directory Project (ODP) is the community that runs and maintains the DMOZ directory.
You can create multi-directive meta tags by using commas instead of one tag for each directive. In fact, because many robots meta tags use "noindex, nofollow" values, you'll see this quite frequently:
Meta name=robots" content="noindex, nofollow" />
How to use meta robots tag for SEO?
Meta robots also adds an extra layer of security to pages that have been blocked in your robots.txt file. Those pages may still be indexed if Google finds them via an external backlink. This can be avoided by not indexing the page.
To prevent a page from being indexed and links from being followed, use the robots meta tag as follows:
<meta name=”robots” content=”noindex,nofollow’>
The meta robots tag's most commonly used values are noindex and nofollow. However, the following values have SEO value as well:
NoImageIndex: Tells search engines not to crawl the images on a page.
None: This is equivalent to combining "noindex, nofollow" into a single value. Crawlers will not index the page or follow any links.
archive: Prevent search engines from displaying a cached version of your page. Ensure that your audience is always seeing the most recent version of your content. MSN/Live uses "NoCache" instead of "archive."
NoSnippet: This prevents search engines from displaying your site's snippet in search results as well as displaying a cached version of the page.
If the whole point of SEO is to get pages into search results, how do a page's meta robots help SEO?
It stops private files and folders from being indexed and displayed in search results. It is generally recommended that you do not publish or password-protect this content on your website. If you must include it for some reason, the robot's meta tag will keep it out of Google.
It makes it easier for search engines to crawl your site. Because search robots have limited crawl budgets, they could theoretically spend all of their time crawling pages for which you don't care about ranking while ignoring your most important ones. Blocking indexing of these unimportant files will assist crawlers in navigating to your more valuable pages.
If you have a page with a lot of link juice but don't want it indexed, you can use the following directive to pass that link juice to other pages on your site.
While it is never a good idea to publish sensitive information on your website, it does happen from time to time. Blocking these URLs with robots.txt tells anyone who reads it to take a look at those pages. Adding "noindex" to a meta robots tag will keep that page out of search results while still putting it somewhere where people can find it.
The most important aspect of using the robot's meta tag is that you use it correctly. It is not uncommon for an entire site to be deindexed because the robot noindex tag was accidentally added to the entire site. Understanding how the robot's meta tag works are therefore critical for SEO.
Conclusion
Understanding and managing your website's crawling and indexing is the foundation of SEO. Technical SEO can be challenging, but the robot's meta tags are nothing to be concerned about.
This tag indexes the webpage on which it is placed. It's the equivalent of telling someone who is going to get a glass of water. Because, once again, search engines index your site by default even if you do not use this code.
Start using PagesMeter now!
With PagesMeter, you have everything you need for better website speed monitoring, all in one place.
- Free Sign Up
- No credit card required
The hreflang attribute is used to specify which language your content is in and which geographical region it is intended for.

A search engine spider has a "allowance" for how many pages on your site it can and wants to crawl. This is referred to as a "crawl budget."

The URL redirect also known as URL forwarding is a technique to give more than one URL address to a page or as a whole website or an application.
Uncover your website’s SEO potential.
PagesMeter is a single tool that offers everything you need to monitor your website's speed.